Masked Auto-Regressive Variational Acceleration: Fast Inference Makes Practical Reinforcement Learning
CVPR 2026

Abstract
Masked auto-regressive diffusion models (MAR) benefit from the expressive modeling ability of diffusion models and the flexibility of masked auto-regressive ordering. However, vanilla MAR suffers from slow inference due to its hierarchical inference mechanism: an outer AR unmasking loop and an inner diffusion denoising chain. Such decoupled structure not only harms the generation efficiency but also hinders the practical use of MAR for reinforcement learning (RL), an increasingly critical paradigm for generative model post-training. To address this fundamental issue, we introduce MARVAL (Masked Auto-regressive Variational Acceleration), a distillation-based framework that compresses the diffusion chain into a single AR generation step while preserving the flexible auto-regressive unmasking order. Such a distillation with MARVAL not only yields substantial inference acceleration but, crucially, makes RL post-training with verifiable rewards practical, resulting in scalable yet human-preferred fast generative models. Our contributions are twofold: (1) a novel score-based variational objective for distilling masked auto-regressive diffusion models into a single generation step without sacrificing sample quality; and (2) an efficient RL framework for masked auto-regressive models via MARVAL-RL. On ImageNet 256×256, MARVAL-Huge achieves an FID of 2.00 with more than 30 times speedup compared with MAR-diffusion, and MARVAL-RL yields consistent improvements in CLIP and image-reward scores on ImageNet datasets with entity names. In conclusion, MARVAL demonstrates the first practical path to distillation and RL of masked auto-regressive diffusion models, enabling fast sampling and better preference alignments.
Framework Overview
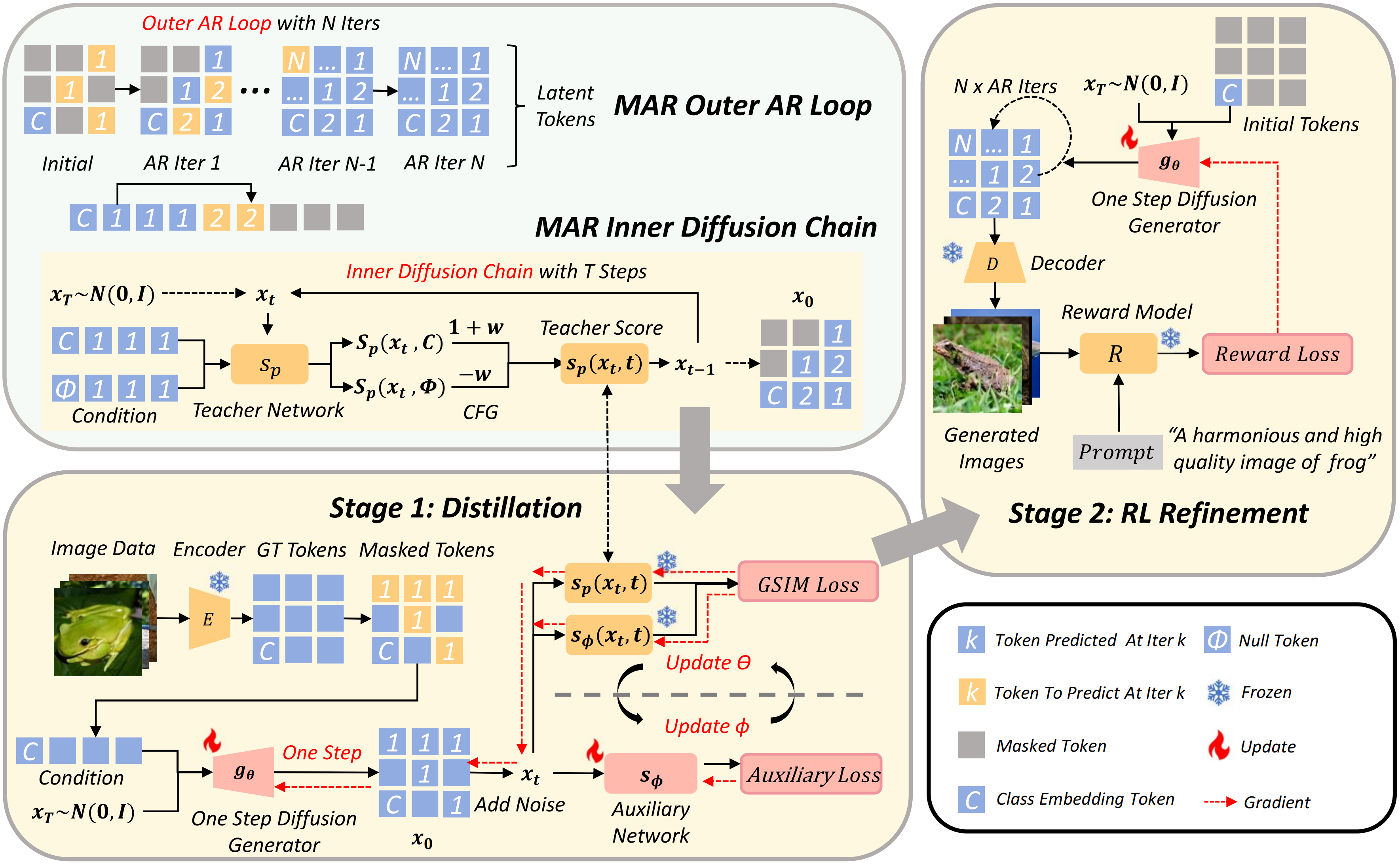
Figure 2. Illustration of our overall framework. (Top-left) The MAR inference process consists of an outer auto-regressive (AR) loop and an inner diffusion chain. Starting from the class embedding token c, MAR performs multiple AR iterations, where each iteration predicts a new subset of latent tokens through a short diffusion process. (Bottom-left) The student one-step generator gθ and the auxiliary network are optimized alternately. In this stage, a portion of tokens is masked, and gθ performs a single AR iteration to predict all masked tokens guided by the teacher MAR model's CFG-based predictions. (Right) The RL refinement stage further improves perceptual fidelity. Here, the distilled generator gθ generates images through multi-step AR inference, and a reward model evaluates the outputs based on textual prompts. The reward loss then fine-tunes gθ to better align with human perceptual preferences.
Method Summary
MARVAL consists of two main stages: Guided Score Implicit Matching (GSIM) for distillation and MARVAL-RL for reinforcement learning refinement.
Stage 1: GSIM Distillation
MAR uses a bi-level generation pattern: an outer AR loop controls gradual unmasking, while an inner diffusion chain runs at each iteration. GSIM compresses this costly diffusion chain into a single-step generator gθ(z, c), where z is Gaussian noise and c is the autoregressive context (class embeddings, unmasked tokens, mask-position embeddings). The objective minimizes the KL divergence between the student's one-step distribution and the teacher's multi-step distribution. Since KL is intractable, GSIM uses a score-based variational formulation: the KL equals an integral of Fisher divergence over time, expressed as the squared ℓ2 distance between student and teacher score functions. An auxiliary network Sφ approximates the student score; the teacher score uses CFG-guided diffusion. The student and auxiliary parameters are optimized alternately via a gradient-equivalence theorem. Pseudo-Huber distance is used for training stability.
Stage 2: MARVAL-RL
RL cannot be coupled with GSIM because distillation trains on single-step samples (low-fidelity), while inference uses multi-step AR iterations. MARVAL-RL is therefore a separate post-hoc refinement phase. The distilled gθ is treated as a policy that generates xg = Gθ(z, cemb, K) via K AR iterations. A reward model R(xg, promptc) (e.g., PickScore) scores the alignment between the generated image and the textual prompt. The RL objective maximizes expected reward by backpropagating the gradient through the reward signal. This fine-tunes θ to produce outputs that are both consistent with the AR prior and better aligned with human perceptual preferences.
- GSIM: Score-based variational distillation compressing the diffusion chain into a single AR step while preserving flexible unmasking order.
- MARVAL-RL: Post-hoc RL refinement using reward feedback (PickScore) on multi-step AR outputs for better perceptual fidelity and preference alignment.
- Results: MARVAL-H achieves FID 2.00 with 32.95× speedup on MAR-B; MARVAL-RL improves CLIP and ImageReward scores across Base, Large, and Huge scales.
Results
FID 2.00
ImageNet 256×256
30×+
Sampling Speedup
↑ ImageReward
MARVAL-RL Gains
Citation
@inproceedings{gu2026marval,
title = {Masked Auto-Regressive Variational Acceleration: Fast Inference Makes Practical Reinforcement Learning},
author = {Gu, Yuxuan and Bai, Weimin and Wang, Yifei and Luo, Weijian and Sun, He},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}